折腾了这么久,终于把这个博客搭起来,作为第一篇文章,就挑了基础的爪哇字符串来写了。博客搭建过程多得土川大佬的指导,非常感谢!附上大佬的博客地址:土川的自留地
String
1 public final class String implements java.io.Serializable, Comparable<String>, CharSequence{}
String在jdk源码中被声明为,是一个不可变类,String对象一旦被创建,其值将不能被改变,但String对象的引用是可变的
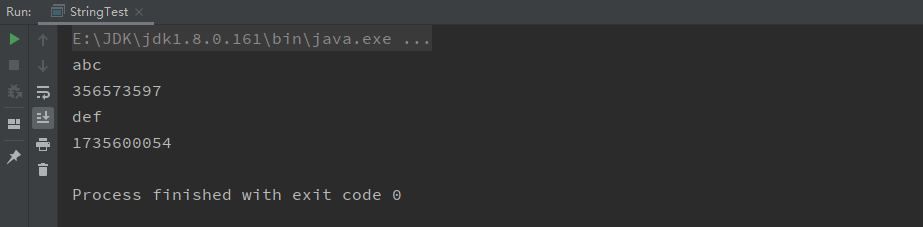
1 2 3 4 5 6 7 8 public static void main(String[] args) { String str = "abc"; System.out.println(str); System.out.println(System.identityHashCode(str)); str = "def"; System.out.println(str); System.out.println(System.identityHashCode(str)); }
以上代码中,创建了一个名为str的String对象并赋值为”abc”,后面经过str = “def”后,虽然输出str的值是变化了,但只是在字符串常量池创建了一个新的”def”,并把str的引用指向了它,并不是改变了原来字符串对象中”abc”的值,我们可以通过打印str=”def”前后的内存地址看出来。
虽然String是不可变的,但比较两个String对象是否相等不建议使用==,而是使用String重写继承自Object的eqauls()。
1.对于String常量s1 和 s2来说,其实其引用指向的都是字符串常量池中同一个字符串,所以使用==来比较这两个字符串,也是返回true。
2.对于s1 和 s3来说,s1是先去字符串常量中寻找是否有”abc”这个字符串,如果有,就把s1的引用指向它,如果没有,就生成一个”abc”字符串,放入字符串常量池中,并把s1的引用指向它;而对于String s3 = new String(“abc”),如果常量池已有了”abc”,则只会在堆中生成一个新的值为”abc”的String对象,并把其引用给s3,如果常量池没有”abc”,这行代码则会生成两个值为”abc”的String对象,一个放入常量池中,一个在堆中,并把堆中的”abc”的引用给s3。
1 2 3 4 5 6 7 8 9 public static void main(String[] args) { String s1 = "abc"; String s2 = "abc"; String s3 = new String("abc"); System.out.println(s1 == s2);//true System.out.println(s1 == s3);//false System.out.println(s1.equals(s3));//true }
jdk1.8中String的eqauls()重写如下,使用eqauls来比较可以准确地判断两个String对象是否相等:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 /** * Compares this string to the specified object. The result is {@code * true} if and only if the argument is not {@code null} and is a {@code * String} object that represents the same sequence of characters as this * object. * * @param anObject * The object to compare this {@code String} against * * @return {@code true} if the given object represents a {@code String} * equivalent to this string, {@code false} otherwise * * @see #compareTo(String) * @see #equalsIgnoreCase(String) */ public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
StringBuffer
StringBuilder
三者对比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class StringTest { public static void main(String[] args) { runAppend(100000); } public static void runAppend(int n) { String str = ""; Long strTimeStart = System.currentTimeMillis(); for (int i= 0; i < n; i++) { str += "" + i; } Long strTimeEnd = System.currentTimeMillis(); System.out.println("append [" + n +"] times String cost time:" + (strTimeEnd-strTimeStart) + "ms"); StringBuffer sb = new StringBuffer(); Long sbTimeStart = System.currentTimeMillis(); for(int i = 0; i < n; i++) { sb.append("" + i); } Long sbTimeEnd = System.currentTimeMillis(); System.out.println("append [" + n +"] times StringBuffer cost time:" + (sbTimeEnd-sbTimeStart) + "ms"); StringBuilder sd = new StringBuilder(); Long sdTimeStart = System.currentTimeMillis(); for(int i = 0; i < n; i++) { sd.append("" + i); } Long sdTimeEnd = System.currentTimeMillis(); System.out.println("append [" + n +"] times StringBuilder cost time:" + (sdTimeEnd-sdTimeStart) + "ms"); } }
用以上代码验证三者的执行速度
当n = 1000 时,可以看出String比StringBuffer和StringBuilder慢一些,但StringBuffer比StringBuilder慢了1ms
当n = 100000 时:
我们可以把数据规模提高到1000000,因为此时String已经需要花费比较长时间了,我们可以把相关代码注释,只比较StringBuffer和StringBuilder
总结
本文链接: https://highphone.xyz/c570fbf2.html